Recently, I did a session at local user group in Ljubljana, Slovenija, where I introduced the new algorithms that are available with MicrosoftML package for Microsoft R Server 9.0.3.
For dataset, I have used two from (still currently) running sessions from Kaggle. In the last part, I did image detection and prediction of MNIST dataset and compared the performance and accuracy between.
MNIST Handwritten digit database is available here.

Starting off with rxNeuralNet, we have to build a NET# model or Neural network to work it’s way.
Model for Neural network:
const { T = true; F = false; }
input Picture [28, 28];
hidden C1 [5 * 13^2]
from Picture convolve {
InputShape = [28, 28];
UpperPad = [ 1, 1];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden C2 [50, 5, 5]
from C1 convolve {
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [ F, T, T];
MapCount = 10;
}
hidden H3 [100]
from C2 all;
// Output layer definition.
output Result [10]
from H3 all;
Once we have this, we can work out with rxNeuralNet algorithm:
model_DNN_GPU <- rxNeuralNet(label ~. ,data = dataTrain ,type = "multi" ,numIterations = 10 ,normalize = "no" #,acceleration = "gpu" #enable this if you have CUDA driver ,miniBatchSize = 64 #set to 1 else set to 64 if you have CUDA driver problem ,netDefinition = netDefinition ,optimizer = sgd(learningRate = 0.1, lRateRedRatio = 0.9, lRateRedFreq = 10) )
Then do the prediction and calculate accuracy matrix:
DNN_GPU_score <- rxPredict(model_DNN_GPU, dataTest, extraVarsToWrite = "label") sum(Score_DNN$Label == DNN_GPU_score$PredictedLabel)/dim(DNN_GPU_score)[1]
Accuracy for this model is:
[1] 0.9789
When working with H2O package, the following code was executed to get same paramethers for Neural network:
model_h20 <- h2o.deeplearning(x = 2:785 ,y = 1 # label for label ,training_frame = train_h2o ,activation = "RectifierWithDropout" ,input_dropout_ratio = 0.2 # % of inputs dropout ,hidden_dropout_ratios = c(0.5,0.5) # % for nodes dropout ,balance_classes = TRUE ,hidden = c(50,100,100) ,momentum_stable = 0.99 ,nesterov_accelerated_gradient = T # use it for speed ,epochs = 15)
When results of test dataset against the learned model is executed:
h2o.confusionMatrix(model_h20) 100-(416/9978)*100
the result is confusion matrix for accuracy of predicted values with value of:
# [1] 95.83083
For comparison, I have added xgBoost (eXtrem Gradient Boosting), but this time, I will not focus on this one.
Time comparison against the packages (in seconds), from left to right are: H20, MicrosoftML with GPU acceleration, MicrosoftML without GPU acceleration and xgBoost.
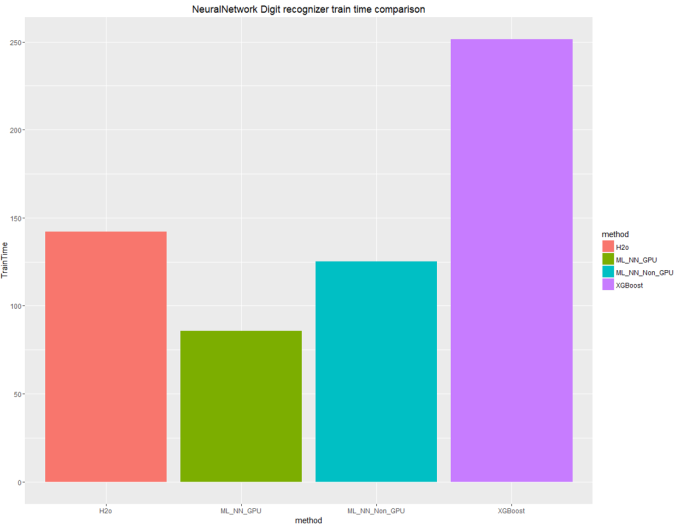
As for the accuracy of the trained model, here are results (based on my tests):
MicrosoftML – Neural Network – 97,8%
H20 – Deep Learning – 95,3 %
xgBoost – 94,9 %
As always, code and dataset are available at GitHub.
Happy R-ing 🙂




[…] Tomaz Kastrun compares a few different libraries in terms of handwritten numeric character recognit…: […]
LikeLike
Hi,
I realy enjoyed from the code you shared at Github and was able to repeat the results by myself (except for the GPU NN).
I was wondering why did you used different Neuronal architectures in the H2O model (3 dense layers)) and in the rxNeuralNet model (2 convolutional layers and 1 dense layer)? Also are the other parameters are the same? (optimization method etc.)
Thanks,
Itamar
LikeLike
I am also wondering what sense does it have to compare two completely different architectures of NN in two different frameworks. This article is not about “rxNeuralNet vs. H2O” but about comparing Convolution NN with two convolution layers and one hidden layer fitted using SGD against 50-100-100 deep NN fitted using nesterov accelerated gradient. This is expected that convolution NN with these setting after 10 iterations will outperform 50-100-100 NN after 15 epochs. It is also not hard to train NN in H2O that will outperform 97,8% accuracy even in similar time that is presented here.
More interesting can be to see how the training time differs for the same NN architectures with “optimal” (leading the the similar accuracy for each framework) settings of other parameters (algorithm for gradient descent, learning rate, …) in different frameworks.
LikeLike
Can you also share what machine you are using? Thanks.
LikeLike
Hi, yes – common desktop (4Cores, i5, 16GB RAM, NVIDIA graphical card) and a Lenovo laptop (460s series).
best, Tomaž
LikeLike
[…] Tomaz Kastrun recently applied rxNeuralNet to the MNIST database of handwritten digits to compare its performance with two other machine learning packages, h2o and xgboost. The results are summarized in the chart […]
LikeLike
[…] Kastrun recently applied rxNeuralNet to the MNIST database of handwritten digits to compare its performance with two other machine learning packages, h2o and xgboost. The results are summarized in the chart […]
LikeLike
[…] Kastrun recently applied rxNeuralNet to the MNIST database of handwritten digits to compare its performance with two other machine learning packages, h2o and xgboost. The results are summarized in the chart […]
LikeLike
[…] Kastrun recently applied rxNeuralNet to the MNIST database of handwritten digits to compare its performance with two other machine learning packages, h2o and xgboost. The results are summarized in the chart […]
LikeLike
Hi TomazTsql,
In the XGBoost code using Microsoft R, you are not using one-hot encoding (a process to convert all categorical rows to columns of 1/0, example, if a column has three values – married, unmarried, divorced, then convert this 1 column to 3 columns of married_flag, unmarried_flag, divorced_flag and all these flags should have values of 1/0). This process of one-hot encoding is necessary while using the train() function from caret package in CRAN R.
But, in rxFastTrees() is this one-hot encoding needed or not?
Thanks.
LikeLike