R language supports several null-able values and it is relatively important to understand how these values behave, when making data pre-processing and data munging.
In general, R supports:
- NULL
- NA
- NaN
- Inf / -Inf
NULL is an object and is returned when an expression or function results in an undefined value. In R language, NULL (capital letters) is a reserved word and can also be the product of importing data with unknown data type.
NA is a logical constant of length 1 and is an indicator for a missing value.NA (capital letters) is a reserved word and can be coerced to any other data type vector (except raw) and can also be a product when importing data. NA and “NA” (as presented as string) are not interchangeable. NA stands for Not Available.
NaN stands for Not A Number and is a logical vector of a length 1 and applies to numerical values, as well as real and imaginary parts of complex values, but not to values of integer vector. NaN is a reserved word.
Inf and -Inf stands for infinity (or negative infinity) and is a result of storing either a large number or a product that is a result of division by zero. Inf is a reserved word and is – in most cases – product of computations in R language and therefore very rarely a product of data import. Infinite also tells you that the value is not missing and a number!
All four null/missing data types have accompanying logical functions available in base R; returning the TRUE / FALSE for each of particular function: is.null(), is.na(), is.nan(), is.infinite().
General understanding of all values by simply using following code:
#reading documentation on all data types: ?NULL ?NA ?NaN ?Inf #populating variables a <- "NA" b <- "NULL" c <- NULL d <- NA e <- NaN f <- Inf ### Check if variables are same? identical(a,d) # [1] FALSE # NA and NaN are not identical identical(d,e) # [1] FALSE ###checking length of data types length(c) # [1] 0 length(d) # [1] 1 length(e) # [1] 1 length(f) # [1] 1 ###checking data types str(c); class(c); #NULL #[1] "NULL" str(d); class(d); #logi NA #[1] "logical" str(e); class(e); #num NaN #[1] "numeric" str(f); class(f); #num Inf #[1] "numeric"
Getting data from R
Nullable data types can have a different behavior when propagated to e.g.: list or or vectors or data.frame types.
We can test this by creating NULL or NA or NaN vectors and dataframes and observe the behaviour:
#empty vectors for NULL, NA and NaN v1 <- c(NULL, NULL, NULL) v2 <- NULL str(v1); class(v1); mode(v1) str(v2); class(v2); mode(v2) v3 <- c(NA, NA, NA) v4 <- NA str(v3); class(v3); mode(v3) str(v4); class(v4); mode(v4) v5 <- c(NaN, NaN, NaN) v6 <- NaN str(v5); class(v5); mode(v5) str(v6); class(v6); mode(v6)
Clearly, it is evident that the NULL vector will always be an empty one, regardless of the elements it can hold. With NA and NaN, it will be the length of the elements it holds, with a slight difference, that NA will be a vector of class Logical, whereas NaN will be a vector of class numeric.
NULL vector will not change the size but class when combined with a mathematical operation:
#operation on NULL Vector v1 <- c(NULL, NULL, NULL) str(v1) # NULL v1 <- v1+1 str(v1) # num(0)
This will only change the class but not the length and still any of the data will not persist in the vector.
With data.frames it is relatively the same behavior.
#empty data.frame df1 <- data.frame(v1=NA,v2=NA, v3=NA) df2 <- data.frame(v1=NULL, v2=NULL, v3=NULL) df3 <- data.frame(v1=NaN, v2=NaN, V3=NaN) str(df1); str(df2);str(df3)
Dataframe consisting of NULL values for each of the column will presented as dataframe with 0 observations and 0 variables (0 columns and 0 rows). Dataframe with NA and NaN will be of 1 observation and 3 variables, of logical data type and of numerical data type, respectively.
When adding new observations to data frames, different behavior when dealing with NULL, NA or NaN.
Adding to “NA” data.frame:
# adding new rows to existing dataframe df1 <- rbind(df1, data.frame(v1=1, v2=2,v3=3)) #explore data.frame df1
it is clear that new row is added, and when adding a new row (vector) of different size, it will generate error, since the dataframe definitions holds the dimensions. Same behavior is expected when dealing with NaN value. On the other hand, different results when using NULL values:
#df2 will get the dimension definition df2 <- rbind(df2, data.frame(v1=1, v2=2)) #this will generate error since the dimension definition is set df2 <- rbind(df2, data.frame(v1=1, v2=NULL)) #and with NA should be fine df2 <- rbind(df2, data.frame(v1=1, v2=NA))
with first assignment, the df2 will get the dimension definition, albeit the first construction of df2 was a nullable vector with three elements.
NULLable is also a result when we are looking in the vector element that is not existent, due to the fact that is out of boundaries:
l <- list(a=1:10, b=c("a","b","c"), c=seq(0,10,0.5))
l$a
# [1] 1 2 3 4 5 6 7 8 9 10
l$c
# [1] 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0
l$r
# NULL
we are calling the sublist r of list l, which is a NULL value, but is not missing or not existing, it is NULL, which in fact is rather contradictory, since the definition is not set. Different results (Not Available) would be returned when calling a vector element:
v <- c(1:3) v[4] #[1] NA
Boundaries in list and in vector are defined differently for NA and NULL data types.
Getting data from SQL Server
I will use several different data-types deriving from following SQL table.
USE AzureLanding;
GO
CREATE TABLE R_Nullables
(
ID INT IDENTITY(1,1) NOT NULL
,num1 FLOAT
,num2 DECIMAL(20,10)
,num3 INT
,tex1 NVARCHAR(MAX)
,tex2 VARCHAR(100)
,bin1 VARBINARY(MAX)
)
INSERT INTO R_Nullables
SELECT 1.22, 21.535, 245, 'This is Nvarchar text','Varchar text',0x0342342
UNION ALL SELECT 3.4534, 25.5, 45, 'This another Nvarchar text','Varchar text 2',0x03423e3434tg
UNION ALL SELECT NULL, NULL, NULL, NULL,NULL,NULL
UNION ALL SELECT 0, 0, 0, '','',0x
By using RODBC R library, data will be imported in R environment:
library(RODBC)
SQLcon <- odbcDriverConnect('driver={SQL Server};server=TOMAZK\\MSSQLSERVER2017;database=AzureLanding;trusted_connection=true')
# df <- sqlQuery(SQLcon, "SELECT * FROM R_Nullables")
df <- sqlQuery(SQLcon, "SELECT ID ,num1 ,num2 ,num3 ,tex1 ,tex2 FROM R_Nullables")
close(SQLcon)
When SELECT * query is executed, the varbinary data type from SQL Server is represented as 2GiB binary object in R and most likely, you will receive an error, because R will not be able to allocate memory:

After altering the columns, the df object will be created. The presentation is straight-forward, yet somehow puzzling:
ID num1 num2 num3 tex1 tex2
1 1 1.2200 21.535 245 This is Nvarchar text Varchar text
2 2 3.4534 25.500 45 This another Nvarchar text Varchar text 2
3 3 NA NA NA <NA> <NA>
4 4 0.0000 0.000 0
When put side-by-side the output from SQL Server and output in R, there are some differences: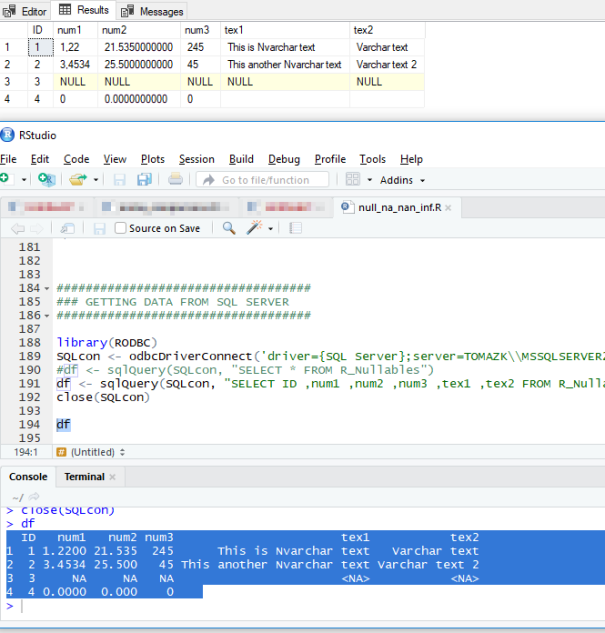
What is presented in SQL Server as NULL value, it is represented in R as NA; which is a logical type, but not the real NA. And only the <NA> is logical object, that is the Not Available information. So this means, that handling NA is not only about the “Not Available” but also the type of “Not Available” information and each of these needs special attention, otherwise when doing some calculations or functions, coerce error will be constantly emerging.
Data imported using SQL Server can be used as normal dataset imported in R in any other way:
#making some elementary calculations df$num1 * 2 # [1] 2.4400 6.9068 NA 0.0000 is.na(df$num1) # [1] FALSE FALSE TRUE FALSE
Same logic applied to text1 and text2 fields. Both are factors, but NULL or NA values can be treated respectively.
# Text df$text2 # NULL df$text1 # NULL
This is rather unexpected, since the SQL Server data types again are not working for R environment. So changing the original SQL query to cast all the values:
df <- sqlQuery(SQLcon, "SELECT ID ,num1 ,num2 ,num3 ,CAST(tex1 AS VARCHAR(100)) as text1 ,CAST(tex2 AS VARCHAR(100)) as text2 FROM R_Nullables")
and rerunning the df population, the result of df$text1 will be:
[1] This is Nvarchar text This another Nvarchar text <NA>
Levels: This another Nvarchar text This is Nvarchar text
Getting data from TXT / CSV files
I have created a sample txt/csv file that will be imported into R by executing:
setwd("C:\\Users\\Tomaz\\")
dft <- read.csv("import_txt_R.txt")
dft
Side-by-side; R and CSV file will show that data types are handled great:

but only on the first glance. Let’s check the last observation by examing the tpye:
is.na(dft[5,]) # text1 text2 val1 val2 #5 TRUE FALSE FALSE FALSE
This is the problem, as the factor and the values of each, will be treated differently, although both are same type, but one is real NA, and the other is not.
identical(class(dft[5,2]),class(dft[5,1])) # [1] TRUE
Before going on next voyage, make sure you check all the data types and values.
As always, code is available at Github. Happy coding! 🙂




Hi, I saw this pop up in r-bloggers and noted a few mistakes.
1/ Generally we talk about special values, not NULL values.
2/ NA is not generally a logical. If NA appears in a `numeric`, it is a special `numeric` (double precision number), if NA appears in an `integer` it is a special integer, and so on for character, complex, etc, but not for raw. There are other specials related to those types, see for example NA_real_ and NA_integer_. To convince yourself, try for example
x
LikeLike
Hi Mark, Thank you for your insight and your point of view on the topics. I do agree it is a topic worth debating (in terms of all the data science topics) and yet this makes it delicate, due to the different views and understanding.
I do agree that not all values are NULL, but somehow I had to wrap it up. And secondly, NA can take any constant type supporting a missing value (character, real, numeric) but itself, it is a logical constant.
Best, Tomaž
LikeLike
[…] article was first published on R – TomazTsql, and kindly contributed to […]
LikeLike
[…] R null values: NULL, NA, NaN, Inf […]
LikeLike
[…] Tomaz Kastrun walks through various special values in R: […]
LikeLike