CSV data format is an old format and very common for data tasks, like import, export or storing. And when it comes performance of creating CSV file, reading and writing CSV files, how does it still stand against some other formats.
We will be looking at benchmarking the CRUD operations with different data formats; from CSV to ORC, Parquet, AVRO and others with the simple Azure data storage operations, like Create, Write, read and transform.
This blogpost will cover:
1. create Azure storage account and set the permissions
2. create connection to SQL Server database using Python
3. export data from SQL Server database (AdventureWorks database) and upload to Azure blob storage and
4. benchmark the performance of different file formats
1. Create Azure storage account
Create Resource group and storage account in your Azure portal. I will name the resource group “RG_BlobStorePyTest“.

Next, for this resource group, I will create a storage account name.
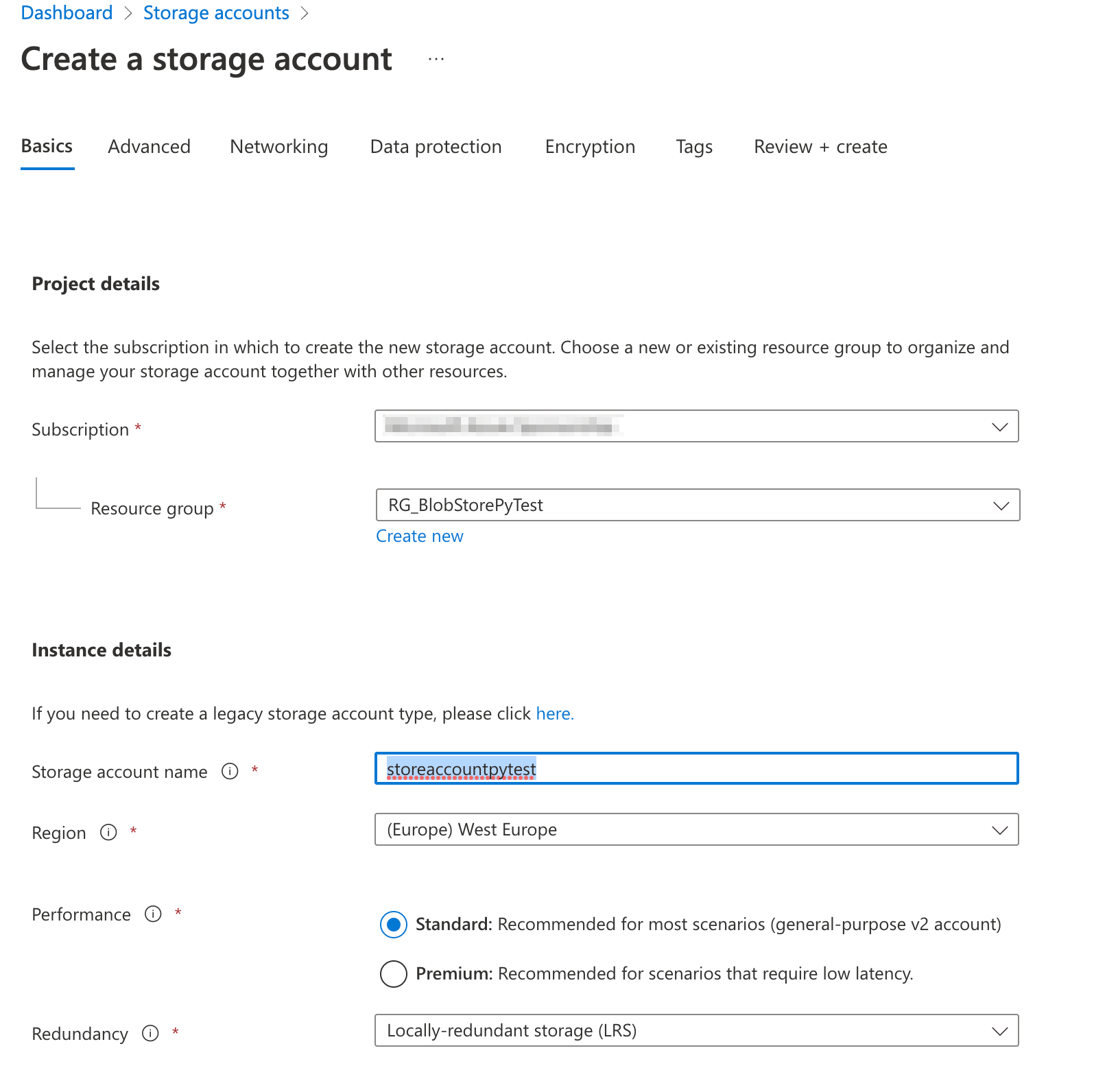
Under the advanced tab, leave the defaults. In particular, I will need “Enable blob public access” to be turned on. And under connectivity, “Public network (all endpoints)” will be selected.
Both tasks can be created using Powershell. With these two commands, and using the same Resource group and storage account names with all the defaults.
#Connect to your Azure subscription
Connect-AzAccount
# Create Resource Group
az group create RG_BlobStorePyTest --location westus2
# Create the storage account
az storage account create -n storeaccountpytest -g RG_BlobStorePyTest
# Create a container object
$ctx = New-AzStorageContext -StorageAccountName storeaccountpytest -UseConnectedAccount
$container = New-AzStorageContainer -Name blobcontainerpytest -Context $ctx
After the Azure storage account and creation of container, we need to get the access to container. We can use SAS (Shared Access Signature). Under the container, click the SAS:

And select the validity of SAS, Allowed services, resource types and permissions:

And click Generate SAS and connection string. Save the credentials for the storage account you have just created.
2. Python and Storage account connection
I will be using Python pypyodbc to connect to local installation of SQL Server. With this package I will be able to get to SQL Server data using ODBC connection.
import sys
import pypyodbc as pyodbc
import datetime
import pandas as pd
# connection parameters
nHost = '(localdb)\MSSQLlocalDB'
nBase = 'AdventureWorks2019'
def sqlconnect(nHost,nBase):
try:
return pyodbc.connect('DRIVER={SQL Server};SERVER='+nHost+';DATABASE='+nBase+';Trusted_connection=yes')
except:
print ("connection failed check authorization parameters")
con = sqlconnect(nHost,nBase)
cursor = con.cursor()
sql = ('''select * from [Sales].[vIndividualCustomer]''')
query = cursor.execute(sql)
row = query.fetchall()
con.close()
# store results to data.frame
df = pd.DataFrame(data=row)
# add column names
df.columns = ['BusinessEntityID','Title','FirstName','MiddleName','LastName','Suffix','PhoneNumber','PhoneNumberType','EmailAddress','EmailPromotion','AddressType','AddressLine1','AddressLine2','City','StateProvinceName','PostalCode','CountryRegionName','Demographics']
In addition, we also need some Python packages to connect to Azure blob storage. Following packages will do most of the work:
from azure.storage.blob import PublicAccess
from azure.storage.blob import BlobServiceClient
import os
But first, we need to do the export.
3. Exporting data from on-prem SQL Server to Blob Store
Exporting can be done simply with writing to a file, which is uploaded to blob store. Following previous Python script block, we will add the output to CSV file.
#to csv
df.to_csv('AWorks2019.csv')
File is created on local machine (host) and can be prepared to be uploaded to the blob store. Make sure you copy and paste the SAS and connection string in the python code accordingly.
from azure.storage.blob import BlobServiceClient, BlobBlock
from azure.storage.blob import PublicAccess
from azure.storage.blob import BlobServiceClient
import os
# Get Connection string from Container SAS. starts with: BlobEndpoint=https:// ...
connection_string = ""
blob_service_client = BlobServiceClient.from_connection_string(connection_string)
container_client = blob_service_client.get_container_client("blobcontainerpytest")
And the last part is to upload the file, that was just created on local machine, to the blob store:
#get name of the file for blob Store
blob_client = container_client.get_blob_client("AWorks2019_Uploaded.csv")
# get the local file name
with open("AWorks2019.csv", "rb") as data:
blob_client.upload_blob(data)
You can upload the file to the file structure or simply upload to root folder of container.

4. Benchmark the performance of different file formats
Last part of this blog post is about performance of different file formats!
CSV format is relative old format. It is almost like an “industry standard”, but this does not make this format always efficient. Especially with writing to CSV file or reading from CSV file. There are other file formats, which can be much more convenient for storing data in the cloud or transferring data between the blob storage containers. Formats like AVRO, Parquet, ORC, pickle can achieve better performance (in terms of writes or reads) and can take up less space on your storage. Since storage is cheap, the network traffic can be expensive, both in time and money.
Let’s compare these files in terms of speed of writing and size itself. I have prepared couple of Python functions:
import timeit
import time
import numpy as np
import pandas as pd
import feather
import pickle
import pyarrow as pa
import pyarrow.orc as orc
from fastavro import writer, reader, parse_schema
number_of_runs = 3
def Create_df():
np.random.seed = 2908
df_size = 1000000
df = pd.DataFrame({
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size)
})
def WRITE_CSV_fun_timeIt():
print('Creating CSV File start')
df.to_csv('10M.csv')
print('Creating CSV File end')
def WRITE_ORC_fun_timeIt():
print('Creating ORC File start')
table = pa.Table.from_pandas(df, preserve_index=False)
orc.write_table(table, '10M.orc')
print('Creating ORC File end')
def WRITE_PARQUET_fun_timeIt():
print('Creating PARQUET File start')
df.to_parquet('10M.parquet')
print('Creating PARQUET File end')
def WRITE_PICKLE_fun_timeIt():
print('Creating PICKLE File start')
with open('10M.pkl', 'wb') as f:
pickle.dump(df, f)
print('Creating PICKLE File end')
This is a sample code, created for purposes of benchmark. In real-case scenario, you would have this a database connector and export the data from SQL Server database to files. But running this code shows that CSV is far the slowest when it comes to writing to a file. In terms of the file size, CSV is also the biggest file.
Run the following script as:
Create_df()
# results for write
print(timeit.Timer(WRITE_CSV_fun_timeIt).timeit(number=number_of_runs))
print(timeit.Timer(WRITE_ORC_fun_timeIt).timeit(number=number_of_runs))
print(timeit.Timer(WRITE_PARQUET_fun_timeIt).timeit(number=number_of_runs))
print(timeit.Timer(WRITE_PICKLE_fun_timeIt).timeit(number=number_of_runs))
CLEAN_files()
And you will see how which format performs. Here is a sample of test:

And you can see, that ORC, Pickle and PARQUET were amongst the fastest one. And the slowest was CSV file format.
Conclusion
Engineering data in fast and scalable way is important aspect of building data lake. With vast majority of different raw files and formats the single and centralised data repository might get swampy. And designing and storing data (especially large amounts of structures, and semi-structured data) in a way, that will give you not only better performances but also give you the freedom of choosing better data formats, is something, that data engineers should do. Ignoring these facts can cripple your performance on a long run.
Sorry for long post, but as always the complete code is available on the Github in the benchmark file formats repository (or click here). Complete Jupyter Notebook is here. And the benchmark Python file is here.
And check Github repository for the future updates.
Happy coding and stay healthy!




[…] From the previous blogpost:– CSV or alternatives? Exporting data from SQL Server data to ORC, AVRO, Parquet, Feather files and st… […]
LikeLike
[…] Tomaz Kastrun tries out several file formats in Azure Data Lake Storage (Gen2): […]
LikeLiked by 1 person