In this Microsoft Fabric series:
- Dec 01: What is Microsoft Fabric?
- Dec 02: Getting started with Microsoft Fabric
- Dec 03: What is lakehouse in Fabric?
- Dec 04: Delta lake and delta tables in Microsoft Fabric
- Dec 05: Getting data into lakehouse
- Dec 06: SQL Analytics endpoint
- Dec 07: SQL commands in SQL Analytics endpoint
- Dec 08: Using Lakehouse REST API
- Dec 09: Building custom environments
- Dec 10: Creating Job Spark definition
- Dec 11: Starting data science with Microsoft Fabric
- Dec 12: Creating data science experiments with Microsoft Fabric
- Dec 13: Creating ML Model with Microsoft Fabric
- Dec 14: Data warehouse with Microsoft Fabric
- Dec 15: Building warehouse with Microsoft Fabric
With the Fabric warehouse created and explored, let’s see, how we can use pipelines to get the data into Fabric warehouse.
In the existing data warehouse, we will introduce new data. By clicking “new data”, two options will be available; pipelines and dataflows. Select the pipelines and give it a name.
For the source, I can create a new Azure SQL Database:

Or we can create a simple ADLS Gen2:

But we will create a new delta table using Spark in datalake. First, we need to create a delta table in Spark:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, LongType, TimestampType, IntegerType, StringType
spark = SparkSession.builder \
.appName("CreateEmptyDeltaTable") \
.config("spark.jars.packages", "io.delta:delta-core_2.12:1.0.0") \
.getOrCreate()
# Define the schema
schema = StructType([
StructField("ID", LongType(), False),
StructField("TimeIngress", TimestampType(), True),
StructField("valOfIngress", IntegerType(), True),
StructField("textIngress", StringType(), True)
])
# Create an empty DataFrame with the specified schema
empty_df = spark.createDataFrame([], schema=schema)
# Write the empty DataFrame as a Delta table
empty_df.write.format("delta").mode("overwrite").save("abfss://1860beee-xxxxxxxxx92e1@onelake.dfs.fabric.microsoft.com/a574dxxxxxxxxx28f/Tables/SampleIngress")
spark.stop()
and we will create another notebook to use it in the pipeline. This notebook will serve only as ingress into the delta table:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, LongType, TimestampType, IntegerType, StringType
from pyspark.sql.functions import col, current_timestamp
import random
import string
# Create a Spark session
spark = SparkSession.builder \
.appName("InsertRandomData2SampleIngressTable") \
.config("spark.jars.packages", "io.delta:delta-core_2.12:1.0.0") \
.getOrCreate()
# Define the schema
schema = StructType([
StructField("ID", LongType(), False),
StructField("TimeIngress", TimestampType(), True),
StructField("valOfIngress", IntegerType(), True),
StructField("textIngress", StringType(), True)
])
random_data = [(id, None, random.randint(1, 100), ''.join(random.choices(string.ascii_letters, k=50))) for id in range(11, 21)]
random_df = spark.createDataFrame(random_data, schema=schema)
random_df.write.format("delta").mode("append").save("abfss://1860beeexxxxxxb92e1@onelake.dfs.fabric.microsoft.com/a574d1a3-xxxxxxxx8f/Tables/SampleIngress")
spark.stop()
And by creating a DWH_pipeline, you can choose copy data from delta table to DWH table
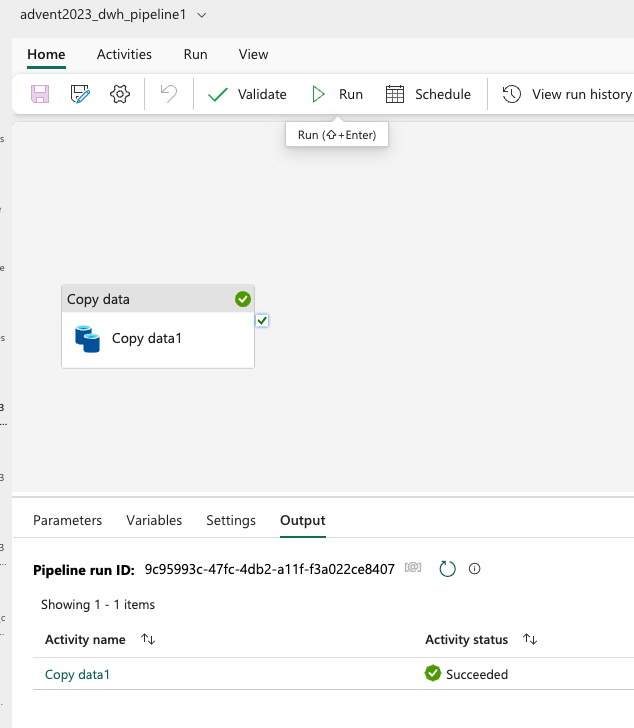
with the following mapping:

So now we have created:
1) notebook for initial delta table creation
2) notebook for inserting random data into the delta table
3) Table in the warehouse as a destination
4) pipeline for copying data from the delta table to the DWH table.
We can also schedule the notebook for inserting random data into the delta table to be executed every 10 seconds and we can schedule the pipeline to run every minute and observe the results.
So we have two schedules:

In data warehouse, we can now observe the records:
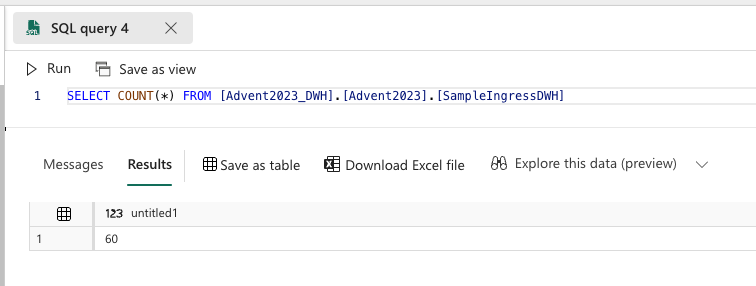
And after two minutes, the final count of rows is growing.

And you can also check for the runs of the notebooks (first print screen) and pipelines (second print screen):


And the best way to check the runs is to use Monitoring hub:

Tomorrow we will looking into the Power BI.
Complete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Microsoft-Fabric
Happy Advent of 2023! 🙂




[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike
[…] Dec 16: Creating data pipelines for Fabric data warehouse […]
LikeLike